
Whether you are a motorsport aerodynamicist squeezing the most simulations out of a limited budget, time and regulations; or a wind engineer modelling city-scale domains, a high-performance CFD solver is key to simulation success.
That’s why ENGYS have spent the last decade relentlessly developing and refining the HELYX-Coupled solver, which now enables the HELYX and ELEMENTS platforms to significantly outperform other commercial codes. Compared with traditional segregated solvers, HELYX-Coupled is at least twice as fast and, in some cases, up to ten times faster, allowing many simulations to finish in half the time than other CFD tools. In fact, HELYX-Coupled is now so fast that a typical steady-state external-aerodynamics case may take longer to mesh than to solve.
So, how has ENGYS engineered its solvers to achieve this? In this article we reveal the techniques behind HELYX-Coupled and how its performance has helped aerodynamicists across the motorsport industry accelerate their CFD development.
Segregated vs Coupled Solver
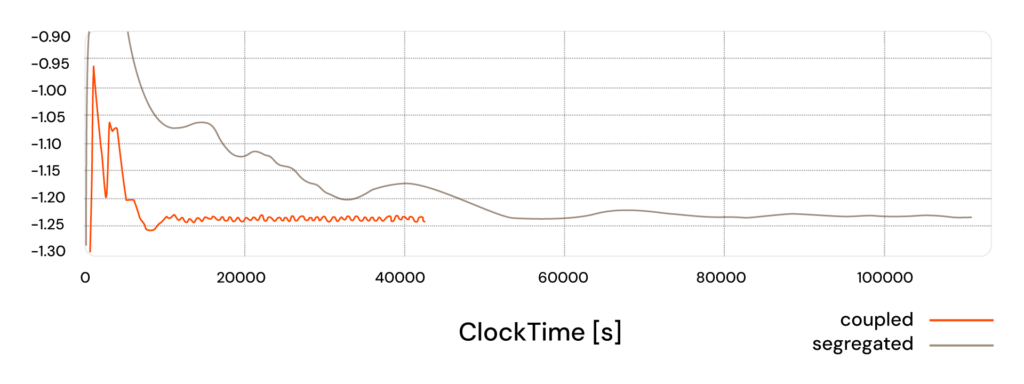
Most industrial CFD workflows still default to segregated, pressure-based solvers (SIMPLE/PISO family). In this approach, the momentum and pressure (pressure-correction) equations are solved sequentially. Segregated methods are memory-lean, simple and stable, but they can require many iterations to converge, especially when pressure-velocity coupling is strong, meshes are highly anisotropic or tight residual targets are needed.
Coupled (block-coupled) solvers by contrast, solve the momentum–pressure system simultaneously across the domain. Each iteration is more costly in terms of both memory and compute per step, but this method typically needs far fewer iterations, often delivering lower total wall time and improved robustness for stiff problems.
‘Our segregated solver for transient simulations is already very fast, around two to three times faster than traditional segregated solvers,’ says Angus Lock, General Manager at ENGYS. ‘One reason is that our approach reduces the number of pressure-correction iterations.’
‘For steady-state work, we developed our block-coupled solver, HELYX-Coupled, which is at least twice as fast and, in some cases, up to ten times faster than segregated solutions,’ adds Lock. ‘Alongside that, our Unified Solver Framework [USF] brings the many OpenFOAM solvers into a single, unified architecture, and we’ve layered in a range of further optimisations.’
One of the techniques employed by HELYX-Coupled involves local time stepping driven by Courant (CFL) scaling to maximise throughput. Each control volume advances with its own pseudo-time step so the local Courant number sits near an optimal target: smooth-flow regions take larger steps, while high-gradient areas take smaller, stability-preserving steps. This results in a more uniform convergence across the field, fewer pressure-correction cycles, and shorter wall time, without compromising accuracy.
A further advantage is reduced operator input complexity because instead of hand-tuning global time steps, under-relaxation or case-specific configurations, users can rely on sensible defaults while the controller adapts automatically, cutting setup time and the risk of unstable or over-damped runs.

Harnessing The Speed Of Single Precision
About twenty years ago, most mainstream x86 CPUs did not show a large real world gap between single precision (FP32) and double precision (FP64) in typical CFD use. Early SIMD generations exposed both FP32 and FP64 vectors, core counts were modest and memory bandwidth per core was relatively comfortable, so many workloads were compute bound. As vector widths increased and cores per socket rose faster than memory channels, a larger share of CFD became memory bound. That shift made the practical benefits of FP32 clearer because halving the data size improves cache residency and reduces pressure on memory bandwidth.
Most CFD codes still default to FP64, which stores 64 bit floating point numbers with about 15 to 16 digits of precision under IEEE 754 [1]. FP64 offers numerical headroom and a wider dynamic range, but the trade off is a larger working set and higher memory traffic. In memory bound solvers this extra traffic dominates wall time far more than raw floating point throughput.
FP32 uses 32 bit numbers with about 7 to 8 digits of precision. It halves storage and memory bandwidth per operation, improves cache hit rates and reduces communication costs for parallel runs. HELYX supports FP32 end to end in both the segregated and HELYX-Coupled solvers. In steady state and transient benchmarks HELYX typically achieves around 40% shorter runtimes with validated settings, whilst maintaining engineering accuracy for external aerodynamics and many RANS cases. Where sensitivity is high or accumulations are long, FP64 remains available per model or per field so users can choose the precision mix that best fits their targets.
‘Double precision stores twice the data per number compared with single precision, so far more bytes have to move between the memory and CPU,’ explains Lock. ‘For many pressure based CFD workflows the limit is memory bandwidth rather than pure compute, which is why FP32 often gives a very real speed advantage without compromising validated accuracy.’
There is also a strong scaling benefit on many modern core CPUs and in the cloud. As core counts reach 96 or more per socket, memory bandwidth per core becomes the bottleneck well before running out of arithmetic units. FP32’s smaller footprint eases this bottleneck so more of the cores stay busy, maintaining parallel efficiency.
‘On today’s large core count cloud hardware you want every core to be doing useful work,’ highlights Lock. ‘Switching to single precision effectively doubles the usable memory bandwidth per core, which allows HELYX to scale better and finish more jobs on the same infrastructure. Our F1 customers chase every second, but the same effect helps any team moving from an on premises cluster to the cloud.’
The Importance Of High-Quality Meshes
Mesh quality is a first-order driver of both accuracy and runtime. Well-formed cells reduce numerical error, allow larger stable time steps and cut linear solver iterations. Poorly aligned or highly skewed cells do the opposite, forcing smaller steps, extra corrections and longer wall time to hit the same residual targets.
The original snappyHexMesh algorithm in OpenFOAM was co-developed by two of the founders of ENGYS and, at the time, delivered higher overall quality than many alternatives. On complex geometries, however, it could leave gaps or thinning in boundary-layer coverage, which made it harder to achieve low y+ and consistent near-wall resolution.

To address this, ENGYS created helyxHexMesh, an extrude-layer meshing approach that guarantees full boundary-layer coverage and gives direct control of y+, growth rate and layer count. The far field is hex-dominant for efficiency, while near-wall regions use polyhedral elements where this improves orthogonality and reduces skewness. This avoids fragile pyramid chains and wedge transitions that can degrade solver robustness on difficult surfaces.
‘HelyxSolve is now so fast that customers often find meshing takes longer than solving,’ reveals Lock. ‘A typical 250 million cell external-aero case on about 1,000 cores might take 45 to 60 minutes to mesh and around 30 minutes to solve with HELYX-Coupled. We are working on a new mesher that targets a further step change in throughput.’
The Benefits of Open-Source Software
There are clear scalability and cost advantages in building on open-source foundations, which is the case for both HELYX and ELEMENTS. An open-source core removes per-core royalty constraints and encourages transparent, reproducible workflows. In practice this allows ENGYS to offer licensing and deployment models that scale cleanly, so teams can run many jobs in parallel on large core counts without artificial bottlenecks.
By contrast, many proprietary CFD tools gate higher core counts or additional concurrent runs behind extra license tokens. This can slow experimentation and inflate costs as projects grow. An open-source base is a more predictable way to scale throughput, since you can increase hardware and automate job arrays without running into per-core licensing hurdles.
CFD’s GPU Future
As the impressive memory bandwidth and parallel computation capabilities of GPU hardware continues to improve, CFD vendors have been gradually introducing GPU-native solvers that map CFD kernels directly to GPUs instead of treating them as add-on accelerators. This results in faster turnaround at lower hardware and energy cost for suitable workloads.
‘To keep HELYX at the front of the pack, we have been investing in GPU-native solvers with several high-profile customers supporting our efforts,’ concludes Lock. ‘Our first GPU prototype already shows compelling economics; hardware CAPEX reduced by 2 to 3 times, and power and data centre OPEX reduced by 4 to 6 times. In practice this means customers can either save a lot of money or run many more cases for the same budget, whilst keeping accuracy and workflow intact.’

References
[1] 2015. IEEE 754-2019. IEEE Standard for Floating-Point Arithmetic [Online]. IEEE SA
